

Decision Tree Classification का परिचय
Machine Learning ने Data analysis और Classification के क्षेत्र में बड़ा परिवर्तन लाया है, और Decision Tree Classification Algorithm एक ऐसा महत्वपूर्ण Tool है जिसका उपयोग डेटा को विभिन्न categories में विभाजित करने के लिए किया जाता है। इस लेख में, हम Decision Tree Classification Algorithm के बारे में विस्तार से जानेंगे और यह कैसे काम करता है।
Decision Tree क्या है ?
Decision Tree Classification एक Tree के रूप में होता है, जिसमें एक Root Node (node of zero) होता है, और फिर विभिन्न शाखाएँ (branches) उत्पन्न होती हैं। प्रत्येक branch एक फ़ीचर को चयन करती है और उसके आधार पर डेटा को विभिन्न तरीकों से Classify करती है। इस प्रक्रिया को जारी रखने से हम एक Tree का रूप बनता जाता है जिसमें हर Node पर कोई ना कोई निर्णय होता है, और इसके आधार पर हम डेटा को Classification करते हैं।
Decision Tree Classification के अंदर, हर Leaf का चयन वह फ़ीचर होता है जो Data को सबसे अच्छे तरीके से विभाजित कर सकता है। इसके लिए Algorithm विभिन्न Parameters (जैसे कि फ़ीचर की importance, Entropy, और Gini impurity) का उपयोग करता है। इसके बाद, Algorithm डेटा को दो या दो से अधिक subcategories में विभाजित करता है, और इस प्रक्रिया को पुनः करके Tree को बनाता जाता है।
एक Decision Tree का लक्ष्य हमें दिए गए डेटा को सबसे अच्छे तरीके से Classify करने के लिए उपयोगी Decision लेने में मदद करना है। जब Tree तैयार हो जाता है, तो हम इसका उपयोग नए Data को Classify करने के लिए कर सकते हैं, सिर्फ subcategories को चुनकर डेटा को Tree के माध्यम से पास करके।
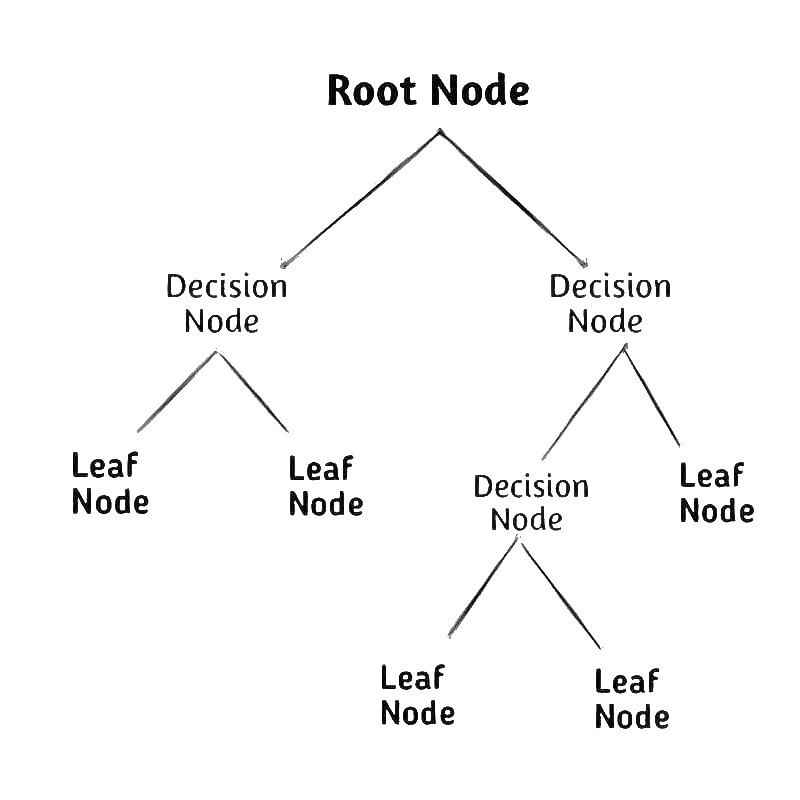
Decision Tree Algorithms कैसे काम करता है?
Decision Tree में, दिए गए Dataset के class को Predict करने के लिए, एल्गोरिदम Tree के Root Node से शुरू होता है। इस एल्गोरिदम में, पेड़ के Root Attribute के Values को रिकॉर्ड (Real Dataset) एट्रिब्यूट के साथ तुलना किया जाता है, और तुलना के आधार पर, वह विशिष्ट Branch का पालन करता है और अगले Node पर Jump करता है।
अगले Node के लिए, एल्गोरिदम फिर से Attribute Value को दूसरे Sub-Node के साथ तुलना करता है और और आगे बढ़ता है। यह प्रक्रिया इसलिए जारी रहती है जब तक वह Tree के Leaf Node तक पहुँचता है।
Decision Tree Classification का काम
Decision Tree Classification का उद्देश्य है कि हम दिए गए Data को सबसे अच्छे तरीके से Classification करें। इसके लिए, यह एक सीखने की प्रक्रिया का follows करता है जिसमें हर Node पर एक फ़ीचर का चयन किया जाता है जो Data को सबसे अच्छे तरीके से विभाजित कर सकता है। इसके बाद, Algorithms डेटा को दो या दो से अधिक subcategories में विभाजित करता है, और इस प्रक्रिया को पुनः करके Treeको बनाता जाता है।
Decision Tree Classification का उपयोग
Decision Tree Classification एक सरल और प्रतिभागी तरीके से data को Classify करने के लिए उपयोगी होता है। यह किसी भी Classification समस्या को हल करने में मदद कर सकता है, चाहे वह customer classification, disease prediction,, या अन्य विशेष Domain का समस्या हो।
Gain Information
Decision Tree Classification एल्गोरिथ्म के internal work का मुख्य आधार फ़ीचरों की महत्वपूर्णता होती है। इसके लिए Algorithm Information Gain करता है, जो एक फ़ीचर के महत्व को मापने के लिए होता है। Algorithm फ़ीचर को चयन करते समय उसके performance की अहमियत को consider करके फ़ीचर का चयन करता है।
Prediction and Data Success
Decision Tree Classification एक डेटा सेट को Prediction करने का एक तरीका भी हो सकता है। एक बार Treeतैयार हो जाता है, तो उसका उपयोग नए डेटा को Classification करने के लिए किया जा सकता है। यह एक महत्वपूर्ण tool है जो विभिन्न Domain में डेटा सफलता की साधना करने में मदद कर सकता है।
Decision Tree के लाभ
- Decision Tree classification Algorithm के कुछ लाभ निम्नलिखित हैं:
- यह एक सरल और समझने में आसान Algorithm है।
- यह बड़े Datasets पर कुशलता से काम करता है।
- यह non-linear data को संभाल सकता है।
- यह नई categories को जोड़ना आसान है।
Conclusion :
Decision Tree Classification एल्गोरिथ्म Machine Learning का एक महत्वपूर्ण Tool है जिसका उपयोग Data Classification के लिए किया जाता है। इसके internal work का मुख्य आधार फ़ीचरों की महत्वपूर्णता होती है और यह एक सीखने की प्रक्रिया का follow करके डेटा को classify करने में मदद करता है।
Read More topic in Machine Learning in Hindi–